
Transformaciones con XSLT
XSLT es un lenguaje que permite transformar documentos XML en cualquier otro tipo documento. Este lenguaje busca dar solución al problema de expresar información estructurada de la forma más abstracta y reutilizable posible. Como veremos más adelante, este lenguaje resulta ideal para innumerables propósitos, ya que permite realizar transformaciones con XSLT de documentos de publicaciones con contenido básico en cualquier tipo de formato de presentación, como un micro sitio con contenido adaptativo a dispositivos móviles, un PDF, o un libro en formato EPUB listo para distribuirse a través de comercios de libros electrónicos.
Comenzaremos explicando los conceptos básicos relacionados con el lenguaje para posteriormente describir la forma en la que lo vamos a utilizar, así como el tipo de procesador XSLT que implementaremos.
Tabla de Contenidos
Elementos en XSLT
XSLT se nutre de dos fuentes principales para funcionar: El documento XML a transformar y la plantilla XSLT de definición de las transformaciones. Estos dos documentos son utilizados por el procesador XSLT para generar un nuevo documento. La Figura 1 muestra la relación entre estos tres elementos.
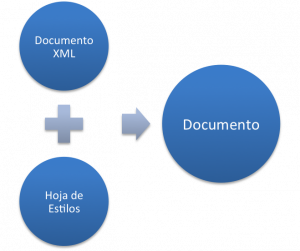
Figura 1: Documentos en XSLT
Tanto el documento XML como la hoja de estilos deben ser documentos XML válidos y bien formados, lo que significa que una hoja de estilos se puede utilizar para transformar otra hoja de estilos.
Documentos XML
Un documento XML contiene elementos estructurados en forma de árbol definidos por medio de etiquetas rodeadas de corchetes angulares y barras (<,> y /). Para que un documento XML esté bien formado se deben seguir unas reglas básicas de estructuración de contenido. Estas reglas son las siguientes:
- Todo documento XML debe estar contenido en un único elemento. Es decir, debe existir un elemento raíz que contenga a todos los demás elementos del documento.
- Todos los elementos deben estar anidados. Si se abre un elemento dentro de otro elemento, el cierre del primer elemento debe aparecer antes del cierre del elemento en el que está contenido, es decir, un elemento no puede contener el cierre de un elemento si no contiene además su apertura.
- Todos los valores de los atributos deben encontrarse entre comillas.
- Las etiquetas XML son sensibles a mayúsculas y minúsculas. Esto es, las etiquetas, “<etiqueta></etiqueta>” y “<Etiqueta></Etiqueta>” son elementos distintos, por lo que “<etiqueta></Etiqueta>” sería un elemento mal formado.
- Todos los elementos de cierre son obligatorios. Si creamos un elemento <img> que contiene otros elementos o contenido de texto, debe incluirse además su etiqueta de cierre </img>.
- Si un elemento está vacío puede introducirse la marca de cierre en la etiqueta de apertura. Es decir, <etiqueta edad=”12”></etiqueta> y <etiqueta edad=”12”/> son elementos idénticos.
Para que además de bien formado, un documento XML sea válido, debe cumplir con esquemas predefinidos que establecen otras restricciones al contenido. Estos esquemas son las Definiciones de Tipo de Documento y los Esquemas XML, que vienen a ser metalenguajes utilizados para definir las características de un vocabulario XML (Doug Tidwell, XSLT.: O’Reilly, 2008). Con estos esquemas podemos definir, por ejemplo, las etiquetas válidas en un documento, así como los atributos que pueden contener. Estos esquemas XML se definen utilizando XML, por tanto, podríamos definir XML como un metalenguaje.
Por tanto, podemos tener un documento bien formado en XML, pero que no sea válido por no cumplir un esquema definido, pero no podemos tener un documento válido que no esté bien formado. En el Fragmento de Código 1 podemos ver un ejemplo de documento XML válido.
<?xml version="1.0" encoding="UTF-8"?> <Coleccion> <documento> <titulo>El Titulo</titulo> <autor>Miguel S. Mendoza</autor> <fecha>2008</fecha> </documento> <documento> <titulo>El Otro Titulo</titulo> <autor>Catalina S. Román</autor> <fecha>2012</fecha> </documento> </Coleccion>
Cabe señalar que aunque existen similitudes entre XML y HTML, no son exactamente lo mismo. Como hemos señalado anteriormente, XML se trata de un metalenguaje que permite definir estructuras XML que definen documentos, mientras que HTML se trata de un lenguaje propiamente dicho, ya que está definido mediante un DTD o esquema XML. Esto provoca que en HTML podamos encontrar estructuras que, aunque se muestran perfectamente en un navegador, rompen las reglas de documentos bien formados definidas anteriormente. Véanse por ejemplo las etiquetas <br>.
En principio, un documento HTML debe “limpiarse” antes de ser utilizado en una transformación XSLT para asegurarse de que es un documento válido. Por suerte podemos realizar este tipo de tareas de una forma sencilla como veremos más adelante.
Hojas de Estilo XSLT
Las hojas de estilo escritas en lenguaje XSLT se basan en patrones o reglas que identifican los elementos del documento a transformar y muestran cómo deben presentarse esos elementos en el documento final.
El elemento raíz de una plantilla XSLT es <xsl:stylesheet> o <xsl:transform> que acostumbra a ir acompañado de los atributos xmlns que define el entorno de nombres de etiquetas que se van a utilizar, y el atributo version, que define la versión del esquema en el que vamos a basar las reglas de transformación.
Dentro de una hoja de estilos podemos encontrar otros elementos como:
- <xsl:output>: Permite definir algunos parámetros del formato de salida, como la codificación, el lenguaje del documento a transformar, la indentación y demás atributos.
- <xsl:variable>: Elemento que va a poder ser accesible en todo el documento de una forma más sencilla sin tener que definirlos cada vez que se vayan a utilizar.
- <xsl:template>: elementos principales de una hoja de estilos ya que definen las transformaciones propiamente dichas. Poseen un atributo denominado match cuyo valor define la expresión que identificará a los elementos del documento XML que se deben transformar con este elemento.
Dentro de un elemento template se encuentra el contenido de la plantilla que define cómo convertir el contenido de la etiqueta XML del documento original. Para definir esta plantilla se pueden utilizar otros elementos de hoja de estilos que permiten realizar diferentes funciones. Entre esos elementos destacan los siguientes:
- <xsl:value-of>: Establece que en el punto en el que se sitúa este elemento debe aparecer el valor del elemento que se corresponda con una expresión concreta que se establece con el atributo select.
- <xsl:for-each>: Permite definir un bucle que se repetirá para todos los elementos que cumplan con una condición establecida en el atributo select del mismo.
- <xsl:choose>: Utilizado en conjunción de los elementos <xsl:when> y <xsl:otherwise> se utiliza para crear estructuras condicionales que nos permitirá establecer un resultado u otro dependiendo de las reglas establecidas en el atributo test del elemento <xsl:when>
Partiendo del documento XML del Fragmento de Código 1, en el Fragmento de Código 2 podemos ver un ejemplo de hoja de estilos XSLT que transformará el documento XML en código HTML.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:template match="/">
<html>
<body>
<h1>Los Documentos</h1>
<table>
<tr>
<th>Titulo</th>
<th>Autor</th>
</tr>
<xsl:for-each select="Coleccion/documento">
<tr>
<td><xsl:value-of select="titulo" /></td>
<xsl:choose>
<xsl:when test="fecha > 2010">
<td style="color: grey">
<xsl:value-of select="autor" />
</td>
</xsl:when>
<xsl:otherwise>
<td style="color: green">
<xsl:value-of select="autor" />
</td>
</xsl:otherwise>
</xsl:choose>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Como consecuencia de aplicar la transformación obtendremos el resultado en código HTML que podemos ver en el Fragmento de Código 3.
<html>
<body>
<h1>Los Documentos</h1>
<table>
<tr>
<th>Titulo</th>
<th>Cuerpo</th>
</tr>
<tr>
<td>El Titulo</td>
<td style="color: green">Miguel S. Mendoza</td>
</tr>
<tr>
<td>El Otro Titulo</td>
<td style="color: grey">Catalina S. Román</td>
</tr>
</table>
</body>
</html>
Esto es solo un pequeño ejemplo de las posibilidades que nos brindan las transformaciones en XSLT ya que existen muchos más elementos que se pueden utilizar dentro de una hoja de estilos XSLT para definir transformaciones.
XPath
Como hemos podido observar hasta ahora, tanto los documentos como las plantillas son documentos XML. Sin embargo, para poder navegar y encontrar elementos XML concretos dentro de un documento debemos utilizar otro lenguaje que nos permita identificar elementos que cumplan ciertos criterios de forma sencilla. En XSLT, el lenguaje que permite realizar estas acciones se denomina XPath y lo hemos podido ver en ejemplos anteriores en los atributos match, test, y select de los elementos <xsl:template>, <xsl:when> y <xsl:value-of> respectivamente.
En XPath todo objeto XML es tratado como un nodo. A su vez, se distinguen siete tipos de nodos:
- Elemento Raíz o Documento: Elemento principal de un documento XML dentro del cual se definen el resto de elementos.
- Elementos: Objetos XML encerrados entre corchetes angulares. Por ejemplo: <autor></autor>.
- Atributo: Propiedad de un elemento cuyo valor se encuentra entrecomillado: Por ejemplo: edad=”23”.
- Texto: Cualquier cadena de texto que se encuentre entrecomillada en un atributo, o dentro de un elemento. Tomando como ejemplo el elemento <autor>Miguel</autor>, el nodo texto sería el valor “Miguel”.
- Comentario: Cadena de texto situada dentro de un elemento entre las cadenas de caracteres “<!–» y “–>”. Por ejemplo: <!– Esto es un comentario –>.
Para relacionar nodos, XPath define cinco parentescos entre ellos:
- Padre: Nodo en el que está contenido un nodo concreto. Todo elemento o atributo posee un nodo padre.
- Hijo: Nodos contenidos en un nodo concreto.
- Hermano: Nodos que poseen el mismo padre.
- Ancestro: Nodo padre de un nodo, así como el nodo padre del nodo padre, etc., es decir, todos los elementos padre desde un nodo concreto hasta el raíz.
- Descendientes: Nodos hijo de un nodo, así como los hijos de cada nodo hijo, etc., es decir, todos los elementos hijo desde un nodo concreto.
XPath define una sintaxis para definir partes en un documento XML. Utiliza expresiones parecidas a las rutas para navegar entre los elementos y contiene una biblioteca de funciones que se utilizan para distinguir elementos.
Las expresiones más comunes en XPath podrían resumirse en las siguientes:
- nombrenodo: Selecciona todos los nodos con el nombre “nombrenodo”.
- /: Selecciona nodos desde el nodo raíz.
- //: Selecciona nodos en el documento desde el nodo actual que cumplan con la selección independientemente de dónde se encuentren.
- .: Selecciona el nodo actual.
- ..: Selecciona el nodo padre.
- @: Selecciona atributos.
Con estas expresiones se pueden construir rutas de navegación como las siguientes:
- documento: Selecciona todos los nodos con el nombre “documento”.
- /Coleccion: Selecciona el nodo raíz “Coleccion”.
- Coleccion/documento: Selecciona todos los elementos “documento” hijos de “Colección”
- //documento: Selecciona todos los elementos “documento” que se encuentren en el documento sin importar su lugar.
- Coleccion//documento: Selecciona todos los elementos “documento” descendientes del elemento “Coleccion”.
- //@edad: Selecciona todos los atributos “edad” del documento.
Además de seleccionar nodos en relación a su posición en el documento, podemos seleccionar nodos concretos dependiendo de ciertas características. Para encontrar nodos que contentan ciertos valores o cumplan ciertas propiedades utilizaremos los denominados “predicados”. Los predicados se incluyen en las expresiones XPath entre corchetes. A continuación podemos ver algunos ejemplos:
- /Coleccion/documento[1]: Selecciona el primer elemento documento hijo del elemento raíz Coleccion.
- /Coleccion/documento[last()-1]: Selecciona el penúltimo elemento documento hijo del elemento raíz Coleccion.
- /Colección/documento[fecha > 2012]/titulo: Selecciona los elementos titulo hijos de los elementos documento, a su vez hijos del elemento raíz Coleccion cuyo valor del elemento fecha sea superior a 2012.
Se pueden anidar expresiones haciendo uso del operador “|”. Por ejemplo:
- //titulo | //autor : Selecciona todos los nodos titulo Y autor del documento.
Por otro lado, se pueden utilizar comodines en las expresiones XPath, lo que nos permite seleccionar nodos dependiendo de expresiones múltiples. Los comodines más habituales son:
- *: Selecciona cualquier nodo elemento.
- @*: Selecciona cualquier nodo atributo.
- node(): Selecciona cualquier nodo de cualquier tipo.
Finalmente, cabe destacar que tanto XSLT como XPath cuentan con una biblioteca de funciones que les permite seleccionar elementos de una forma mucho más eficiente. Podemos encontrar un listado de las mismas en la propia especificación.
Conclusión
En definitiva, XSLT es un lenguaje extremadamente potente que nos permite realizar transformaciones de una forma sencilla y rápida. Aunque la curva de aprendizaje pueda ser un poco complicada, una vez se han realizado unas cuantas transformaciones y se han estudiado correctamente las capacidades de selección de nodos con XPath las posibilidades se abren a cada paso.

1 respuesta
[…] el artículo Transformaciones con XSLT vimos una introducción al lenguaje de transformaciones, sin embargo, no explicamos como utilizar […]